How (and Why) We Back Up ClickUp

Take a look at our ClickUp backup solution. Automated exports, a GitHub repository, and a practical guide to keeping your company data under control.
Why the native export wasn't enough
When you want to back up data from ClickUp today, the first option that comes to mind is the native CSV export. It can be useful in some cases – for reporting or simple data extraction. But as a tool for a complete backup, it falls significantly short, especially when your daily work depends on context, comments, task descriptions, and task hierarchy.
We didn't want a quality backup just to have it sitting somewhere "just in case." We needed the backed-up data to be in a form that could still be meaningfully worked with in the event of a service outage or complete unavailability. That's precisely why we needed to approach the backup more comprehensively.
What risks we wanted to cover
Why back up data at all? What's it actually for? From our perspective, we wanted to cover specific scenarios that could realistically arise in our operations. We tried to answer a few basic questions:
What would we do if one of our spaces was accidentally deleted and couldn't be restored? Or if data was lost for some other reason? That would be a serious problem for how we operate.
What if ClickUp went down? Even a brief outage would be noticeably disruptive to our daily work. And the recent Cloudflare outage was a reminder that these situations aren't purely theoretical.
What if ClickUp experienced a longer-term service disruption or interruption?
And finally: what if we decided in the future to switch to a different SaaS tool for MeasureDesign? Could an existing backup make a potential migration easier?
How we figured out what we actually needed
Based on these questions, we concluded that we needed a solution that would let us automate the backup process. At the same time, we wanted to be able to restore data back into ClickUp and access it in a human-readable form – whether for review, auditing, or simply when no other option was available.
We also needed one more thing: automated monitoring of the entire process. What if something goes wrong with a specific backup on a specific day? We needed to know about it so we could address it, and so that any failure wouldn't go unnoticed.
Our solution in three parts
Based on the requirements described above, we built three tools that together form one functional workflow.
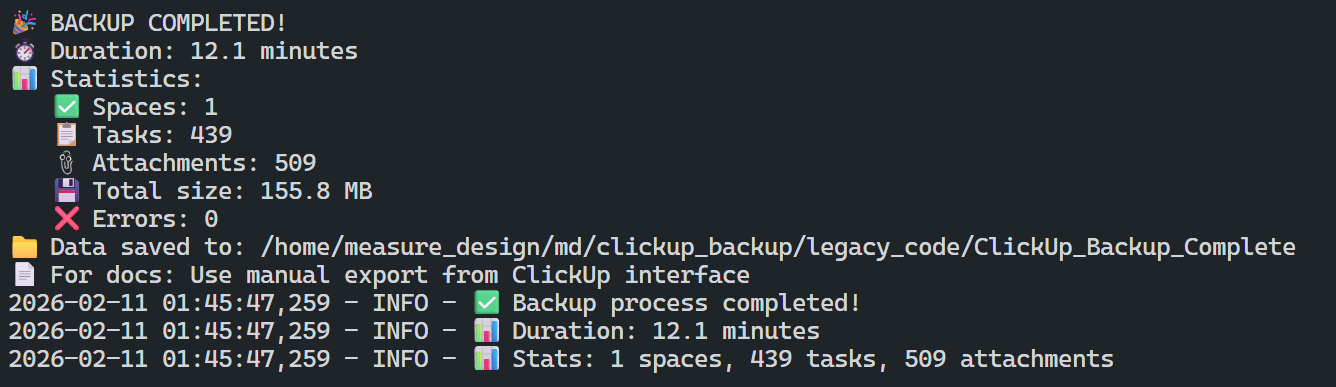
The first is a backup script. It runs every day, accesses ClickUp's API endpoints, and downloads all of our data, including metadata, attachments, and relationships. Subtasks retain information about their parent tasks, and tasks include their text content and attachments. Since we frequently share screenshots and images in tasks, a backup without attachments simply wouldn't be complete.
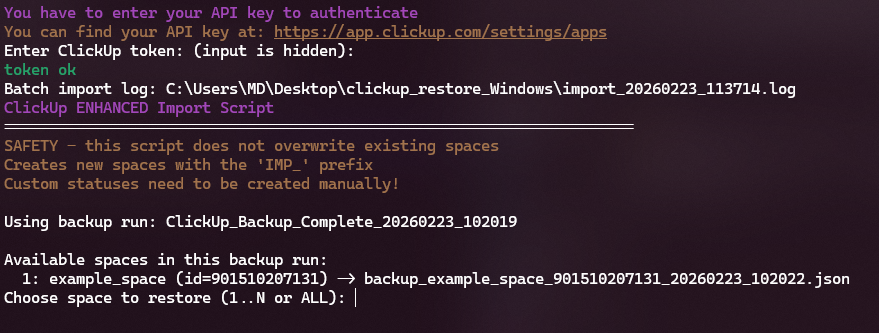
The second tool is a restore script. It lets us push data from the backup back into ClickUp if needed. This script does not modify any existing ClickUp data – it only creates new spaces from the backup, so there's no risk of losing anything else during a restore.
The third component is a viewer. It lets us display the contents of a backup in a readable, easy-to-understand format – essentially a web page you can browse through. Everything is organized hierarchically: spaces contain lists and tasks, and tasks contain their text content, comments, attachments, and images.
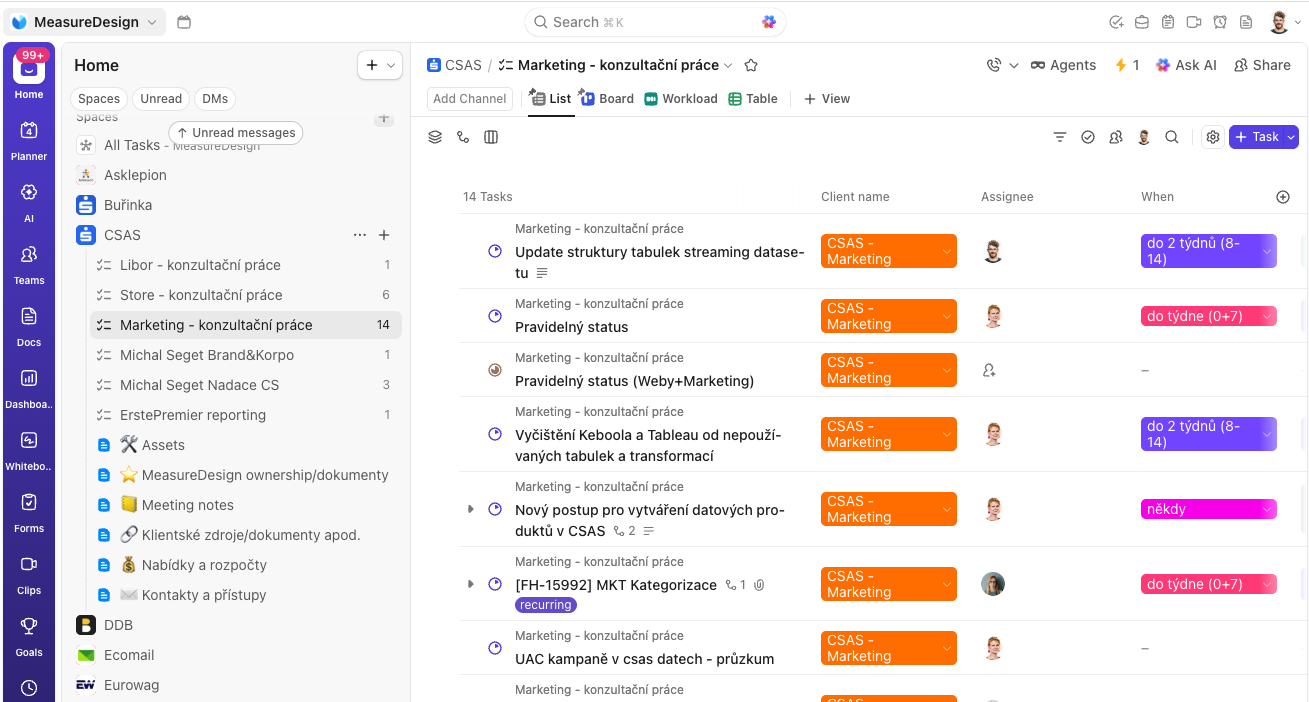
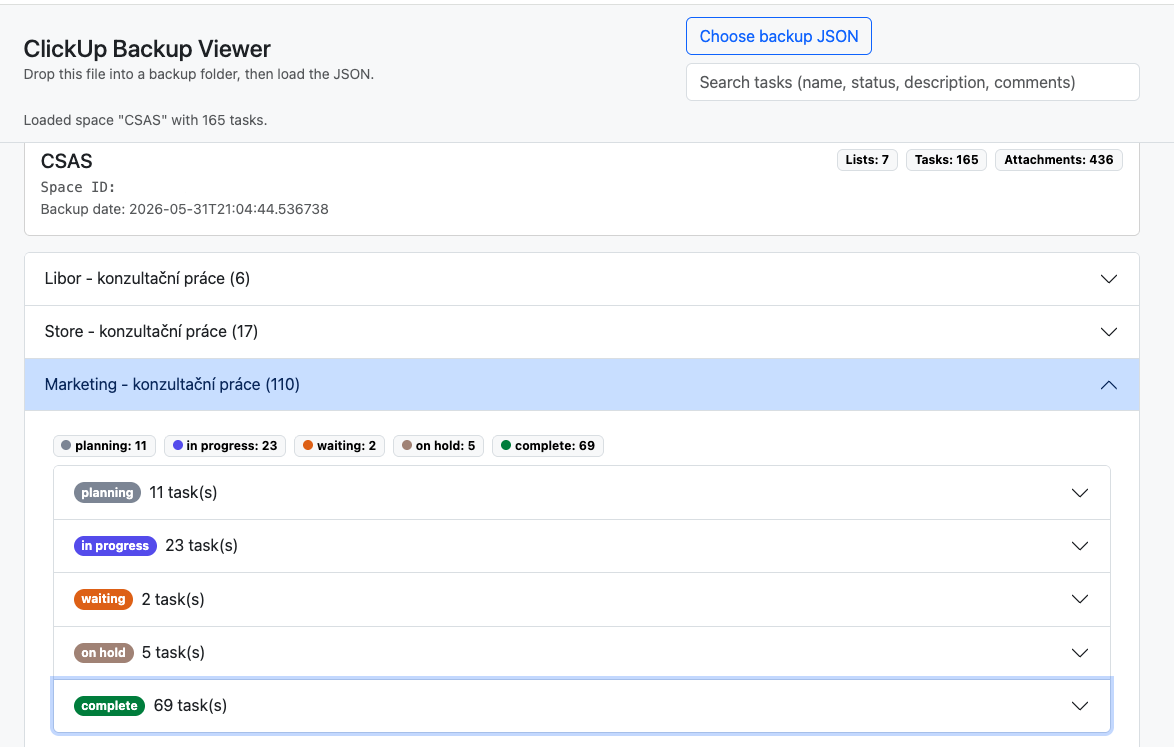
A data backup solves only part of the problem. The other part is whether you can actually use that backup for something meaningful. Our three-part workflow makes that possible.
How we deployed our workflow
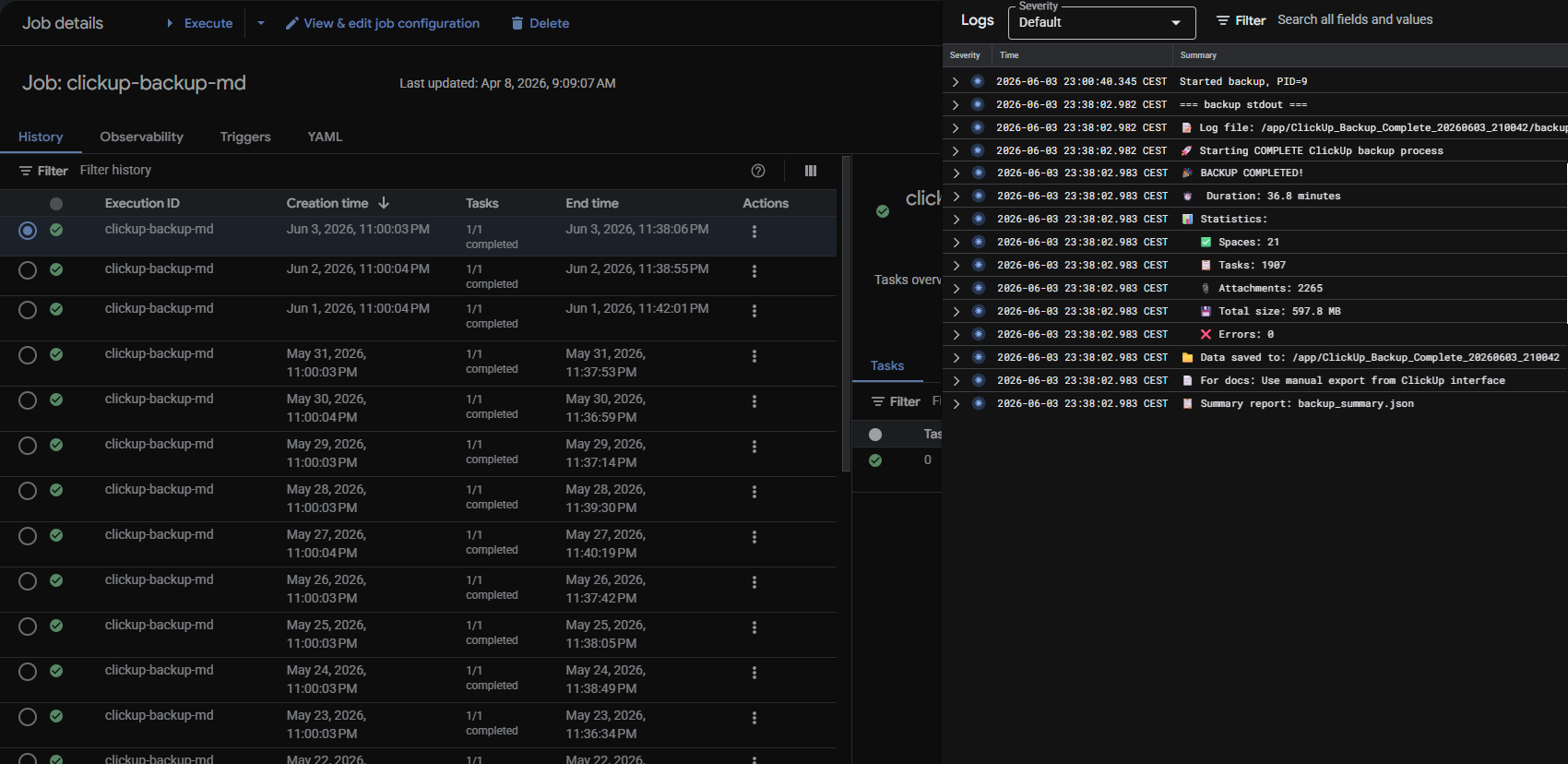
We deployed the backup process to Google Cloud. We use it frequently, so it was a natural fit. The backup runs nightly as a Cloud Run Job – it doesn't depend on any team member's computer and runs automatically on a set schedule. On top of the backup itself, we built monitoring that tracks whether each run succeeds and notifies us immediately if something doesn't go as expected.
Creating the backup isn't enough on its own. It's equally important to know that the backup was actually created and that no issues occurred during the process. That's why, alongside the backup process itself, we also addressed ongoing verification. The monitoring is a separate script that wraps the main backup process, checks whether it completed as expected, and evaluates the log generated during the run. If any errors or issues appear in the log, it automatically notifies us by email.
In our view, a backup that no one verifies isn't really a backup. That's why we don't back up manually – the entire process is automated, repeatable, and its output is regularly checked.
The backup output – all files, attachments, images, and other data – is stored in a dedicated Google Cloud bucket. The backup is therefore stored independently of ClickUp and remains separately accessible if problems arise.
What this means for us
Having a reliable backup gives us greater confidence in our day-to-day operations. We can trust that if an unexpected event occurs, we'll be able to keep working. It also reduces our dependency on a single service and its availability – making us better prepared for potential outages as well as a possible future migration to another service.
Closing thoughts
SaaS tools like ClickUp are great for productivity, and we genuinely enjoy working with it. At the same time, it has become central enough to our work that it now holds a large part of our know-how and information we use on a daily basis. Data this critical shouldn't exist in only one place and in one vendor-defined format.
Our goal wasn't to replace ClickUp, but to complement it with the confidence that we won't lose important data – and that we'll be able to work with it outside of ClickUp if we ever need to.
If our solution caught your interest and you'd like to use it or adapt it for your own needs, the complete technical implementation is available in a public GitHub repository. The repository includes all three parts of the workflow – the backup tool, the restore tool, and the backup viewer – along with documentation for deployment and operation.
The project is published under the MIT license and is provided without any warranties. Use, modification, and deployment are entirely at your own risk.